from fastai.vision.all import *Computer vision intro
Using the fastai library in computer vision.
This tutorial highlights on how to quickly build a Learner and fine tune a pretrained model on most computer vision tasks.
Single-label classification
For this task, we will use the Oxford-IIIT Pet Dataset that contains images of cats and dogs of 37 different breeds. We will first show how to build a simple cat-vs-dog classifier, then a little bit more advanced model that can classify all breeds.
The dataset can be downloaded and decompressed with this line of code:
path = untar_data(URLs.PETS)It will only do this download once, and return the location of the decompressed archive. We can check what is inside with the .ls() method.
path.ls()(#2) [Path('/home/jhoward/.fastai/data/oxford-iiit-pet/images'),Path('/home/jhoward/.fastai/data/oxford-iiit-pet/annotations')]We will ignore the annotations folder for now, and focus on the images one. get_image_files is a fastai function that helps us grab all the image files (recursively) in one folder.
files = get_image_files(path/"images")
len(files)7390Cats vs dogs
To label our data for the cats vs dogs problem, we need to know which filenames are of dog pictures and which ones are of cat pictures. There is an easy way to distinguish: the name of the file begins with a capital for cats, and a lowercased letter for dogs:
files[0],files[6](Path('/home/jhoward/.fastai/data/oxford-iiit-pet/images/basset_hound_181.jpg'),
Path('/home/jhoward/.fastai/data/oxford-iiit-pet/images/beagle_128.jpg'))We can then define an easy label function:
def label_func(f): return f[0].isupper()To get our data ready for a model, we need to put it in a DataLoaders object. Here we have a function that labels using the file names, so we will use ImageDataLoaders.from_name_func. There are other factory methods of ImageDataLoaders that could be more suitable for your problem, so make sure to check them all in vision.data.
dls = ImageDataLoaders.from_name_func(path, files, label_func, item_tfms=Resize(224))We have passed to this function the directory we’re working in, the files we grabbed, our label_func and one last piece as item_tfms: this is a Transform applied on all items of our dataset that will resize each image to 224 by 224, by using a random crop on the largest dimension to make it a square, then resizing to 224 by 224. If we didn’t pass this, we would get an error later as it would be impossible to batch the items together.
We can then check if everything looks okay with the show_batch method (True is for cat, False is for dog):
dls.show_batch()
Then we can create a Learner, which is a fastai object that combines the data and a model for training, and uses transfer learning to fine tune a pretrained model in just two lines of code:
learn = vision_learner(dls, resnet34, metrics=error_rate)
learn.fine_tune(1)| epoch | train_loss | valid_loss | error_rate | time |
|---|---|---|---|---|
| 0 | 0.150819 | 0.023647 | 0.007442 | 00:09 |
| epoch | train_loss | valid_loss | error_rate | time |
|---|---|---|---|---|
| 0 | 0.046232 | 0.011466 | 0.004736 | 00:10 |
The first line downloaded a model called ResNet34, pretrained on ImageNet, and adapted it to our specific problem. It then fine tuned that model and in a relatively short time, we get a model with an error rate of well under 1%… amazing!
If you want to make a prediction on a new image, you can use learn.predict:
learn.predict(files[0])('False', TensorImage(0), TensorImage([9.9998e-01, 2.0999e-05]))The predict method returns three things: the decoded prediction (here False for dog), the index of the predicted class and the tensor of probabilities of all classes in the order of their indexed labels(in this case, the model is quite confident about the being that of a dog). This method accepts a filename, a PIL image or a tensor directly in this case. We can also have a look at some predictions with the show_results method:
learn.show_results()
Check out the other applications like text or tabular, or the other problems covered in this tutorial, and you will see they all share a consistent API for gathering the data and look at it, create a Learner, train the model and look at some predictions.
Classifying breeds
To label our data with the breed name, we will use a regular expression to extract it from the filename. Looking back at a filename, we have:
files[0].name'great_pyrenees_173.jpg'so the class is everything before the last _ followed by some digits. A regular expression that will catch the name is thus:
pat = r'^(.*)_\d+.jpg'Since it’s pretty common to use regular expressions to label the data (often, labels are hidden in the file names), there is a factory method to do just that:
dls = ImageDataLoaders.from_name_re(path, files, pat, item_tfms=Resize(224))Like before, we can then use show_batch to have a look at our data:
dls.show_batch()
Since classifying the exact breed of cats or dogs amongst 37 different breeds is a harder problem, we will slightly change the definition of our DataLoaders to use data augmentation:
dls = ImageDataLoaders.from_name_re(path, files, pat, item_tfms=Resize(460),
batch_tfms=aug_transforms(size=224))This time we resized to a larger size before batching, and we added batch_tfms. aug_transforms is a function that provides a collection of data augmentation transforms with defaults we found that perform well on many datasets. You can customize these transforms by passing appropriate arguments to aug_transforms.
dls.show_batch()
We can then create our Learner exactly as before and train our model.
learn = vision_learner(dls, resnet34, metrics=error_rate)We used the default learning rate before, but we might want to find the best one possible. For this, we can use the learning rate finder:
learn.lr_find()SuggestedLRs(lr_min=0.010000000149011612, lr_steep=0.0063095735386013985)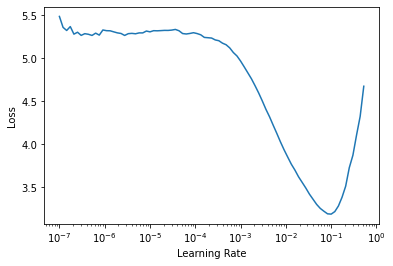
It plots the graph of the learning rate finder and gives us two suggestions (minimum divided by 10 and steepest gradient). Let’s use 3e-3 here. We will also do a bit more epochs:
learn.fine_tune(2, 3e-3)| epoch | train_loss | valid_loss | error_rate | time |
|---|---|---|---|---|
| 0 | 1.270041 | 0.308686 | 0.109608 | 00:16 |
| epoch | train_loss | valid_loss | error_rate | time |
|---|---|---|---|---|
| 0 | 0.468626 | 0.355379 | 0.117050 | 00:21 |
| 1 | 0.418402 | 0.384385 | 0.110961 | 00:20 |
| 2 | 0.267954 | 0.220428 | 0.075778 | 00:21 |
| 3 | 0.143201 | 0.203174 | 0.064953 | 00:20 |
Again, we can have a look at some predictions with show_results:
learn.show_results()
Another thing that is useful is an interpretation object, it can show us where the model made the worse predictions:
interp = Interpretation.from_learner(learn)interp.plot_top_losses(9, figsize=(15,10))
Single-label classification - With the data block API
We can also use the data block API to get our data in a DataLoaders. This is a bit more advanced, so fell free to skip this part if you are not comfortable with learning new API’s just yet.
A datablock is built by giving the fastai library a bunch of informations:
- the types used, through an argument called
blocks: here we have images and categories, so we passImageBlockandCategoryBlock. - how to get the raw items, here our function
get_image_files. - how to label those items, here with the same regular expression as before.
- how to split those items, here with a random splitter.
- the
item_tfmsandbatch_tfmslike before.
pets = DataBlock(blocks=(ImageBlock, CategoryBlock),
get_items=get_image_files,
splitter=RandomSplitter(),
get_y=using_attr(RegexLabeller(r'(.+)_\d+.jpg$'), 'name'),
item_tfms=Resize(460),
batch_tfms=aug_transforms(size=224))The pets object by itself is empty: it only containes the functions that will help us gather the data. We have to call dataloaders method to get a DataLoaders. We pass it the source of the data:
dls = pets.dataloaders(untar_data(URLs.PETS)/"images")Then we can look at some of our pictures with dls.show_batch()
dls.show_batch(max_n=9)
Multi-label classification
For this task, we will use the Pascal Dataset that contains images with different kinds of objects/persons. It’s orginally a dataset for object detection, meaning the task is not only to detect if there is an instance of one class of an image, but to also draw a bounding box around it. Here we will just try to predict all the classes in one given image.
Multi-label classification defers from before in the sense each image does not belong to one category. An image could have a person and a horse inside it for instance. Or have none of the categories we study.
As before, we can download the dataset pretty easily:
path = untar_data(URLs.PASCAL_2007)
path.ls()(#9) [Path('/home/jhoward/.fastai/data/pascal_2007/valid.json'),Path('/home/jhoward/.fastai/data/pascal_2007/test.json'),Path('/home/jhoward/.fastai/data/pascal_2007/test'),Path('/home/jhoward/.fastai/data/pascal_2007/train.json'),Path('/home/jhoward/.fastai/data/pascal_2007/test.csv'),Path('/home/jhoward/.fastai/data/pascal_2007/models'),Path('/home/jhoward/.fastai/data/pascal_2007/segmentation'),Path('/home/jhoward/.fastai/data/pascal_2007/train.csv'),Path('/home/jhoward/.fastai/data/pascal_2007/train')]The information about the labels of each image is in the file named train.csv. We load it using pandas:
df = pd.read_csv(path/'train.csv')
df.head()| fname | labels | is_valid | |
|---|---|---|---|
| 0 | 000005.jpg | chair | True |
| 1 | 000007.jpg | car | True |
| 2 | 000009.jpg | horse person | True |
| 3 | 000012.jpg | car | False |
| 4 | 000016.jpg | bicycle | True |
Multi-label classification - Using the high-level API
That’s pretty straightforward: for each filename, we get the different labels (separated by space) and the last column tells if it’s in the validation set or not. To get this in DataLoaders quickly, we have a factory method, from_df. We can specify the underlying path where all the images are, an additional folder to add between the base path and the filenames (here train), the valid_col to consider for the validation set (if we don’t specify this, we take a random subset), a label_delim to split the labels and, as before, item_tfms and batch_tfms.
Note that we don’t have to specify the fn_col and the label_col because they default to the first and second column respectively.
dls = ImageDataLoaders.from_df(df, path, folder='train', valid_col='is_valid', label_delim=' ',
item_tfms=Resize(460), batch_tfms=aug_transforms(size=224))As before, we can then have a look at the data with the show_batch method.
dls.show_batch()
Training a model is as easy as before: the same functions can be applied and the fastai library will automatically detect that we are in a multi-label problem, thus picking the right loss function. The only difference is in the metric we pass: error_rate will not work for a multi-label problem, but we can use accuracy_thresh and F1ScoreMulti. We can also change the default name for a metric, for instance, we may want to see F1 scores with macro and samples averaging.
f1_macro = F1ScoreMulti(thresh=0.5, average='macro')
f1_macro.name = 'F1(macro)'
f1_samples = F1ScoreMulti(thresh=0.5, average='samples')
f1_samples.name = 'F1(samples)'
learn = vision_learner(dls, resnet50, metrics=[partial(accuracy_multi, thresh=0.5), f1_macro, f1_samples])As before, we can use learn.lr_find to pick a good learning rate:
learn.lr_find()SuggestedLRs(lr_min=0.025118863582611083, lr_steep=0.03981071710586548)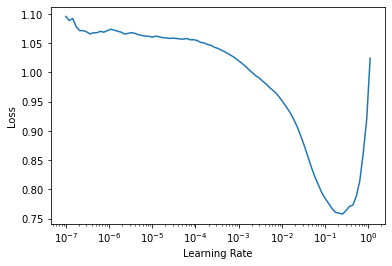
We can pick the suggested learning rate and fine-tune our pretrained model:
learn.fine_tune(2, 3e-2)| epoch | train_loss | valid_loss | accuracy_multi | time |
|---|---|---|---|---|
| 0 | 0.437855 | 0.136942 | 0.954801 | 00:17 |
| epoch | train_loss | valid_loss | accuracy_multi | time |
|---|---|---|---|---|
| 0 | 0.156202 | 0.465557 | 0.914801 | 00:20 |
| 1 | 0.179814 | 0.382907 | 0.930040 | 00:20 |
| 2 | 0.157007 | 0.129412 | 0.953924 | 00:20 |
| 3 | 0.125787 | 0.109033 | 0.960856 | 00:19 |
Like before, we can easily have a look at the results:
learn.show_results()
Or get the predictions on a given image:
learn.predict(path/'train/000005.jpg')((#2) ['chair','diningtable'],
TensorImage([False, False, False, False, False, False, False, False, True, False,
True, False, False, False, False, False, False, False, False, False]),
TensorImage([1.6750e-03, 5.3663e-03, 1.6378e-03, 2.2269e-03, 5.8645e-02, 6.3422e-03,
5.6991e-03, 1.3682e-02, 8.6864e-01, 9.7093e-04, 6.4747e-01, 4.1217e-03,
1.2410e-03, 2.9412e-03, 4.7769e-01, 9.9664e-02, 4.5190e-04, 6.3532e-02,
6.4487e-03, 1.6339e-01]))As for the single classification predictions, we get three things. The last one is the prediction of the model on each class (going from 0 to 1). The second to last cooresponds to a one-hot encoded targets (you get True for all predicted classes, the ones that get a probability > 0.5) and the first is the decoded, readable version.
And like before, we can check where the model did its worse:
interp = Interpretation.from_learner(learn)
interp.plot_top_losses(9)| target | predicted | probabilities | loss | |
|---|---|---|---|---|
| 0 | car;person;tvmonitor | car | tensor([7.2388e-12, 5.9609e-06, 1.7054e-11, 3.8985e-09, 7.7078e-12, 3.4044e-07,\n 9.9999e-01, 7.2118e-12, 1.0105e-05, 3.1035e-09, 2.3334e-09, 9.1077e-09,\n 1.6201e-09, 1.1083e-08, 1.0809e-02, 2.1072e-07, 9.5961e-16, 5.0478e-07,\n 4.4531e-10, 9.6444e-12]) | 1.494603157043457 |
| 1 | boat | car | tensor([8.3430e-06, 1.9416e-03, 6.9865e-06, 1.2985e-04, 1.6142e-06, 8.2200e-05,\n 9.9698e-01, 1.3143e-06, 1.0047e-03, 4.9794e-05, 1.9155e-05, 4.7409e-05,\n 7.5056e-05, 1.6572e-05, 3.4760e-02, 6.9266e-04, 1.3006e-07, 6.0702e-04,\n 1.5781e-05, 1.9860e-06]) | 0.7395917773246765 |
| 2 | bus;car | car | tensor([2.2509e-11, 1.0772e-05, 6.0177e-11, 4.8728e-09, 1.7920e-11, 4.8695e-07,\n 9.9999e-01, 9.0638e-12, 1.9819e-05, 8.8023e-09, 5.1272e-09, 2.3535e-08,\n 6.0401e-09, 7.2609e-09, 4.4117e-03, 4.8268e-07, 1.2528e-14, 1.2667e-06,\n 8.2282e-10, 1.6300e-11]) | 0.7269787192344666 |
| 3 | chair;diningtable;person | person;train | tensor([1.6638e-03, 2.0881e-02, 4.7525e-03, 2.6422e-02, 6.2972e-04, 4.7170e-02,\n 1.2263e-01, 2.9744e-03, 5.5352e-03, 7.1830e-03, 1.0062e-03, 2.6123e-03,\n 1.8208e-02, 5.9618e-02, 7.6859e-01, 3.3504e-03, 1.1324e-03, 2.3881e-03,\n 6.5440e-01, 1.7040e-03]) | 0.6879587769508362 |
| 4 | boat;chair;diningtable;person | person | tensor([0.0058, 0.0461, 0.0068, 0.1083, 0.0094, 0.0212, 0.4400, 0.0047, 0.0166,\n 0.0054, 0.0030, 0.0258, 0.0020, 0.0800, 0.5880, 0.0147, 0.0026, 0.1440,\n 0.0219, 0.0166]) | 0.6826764941215515 |
| 5 | bicycle;car;person | car | tensor([3.6825e-09, 7.3755e-05, 1.7181e-08, 4.5056e-07, 3.5667e-09, 1.0882e-05,\n 9.9939e-01, 6.0704e-09, 5.7179e-05, 3.8519e-07, 9.3825e-08, 6.1463e-07,\n 3.9191e-07, 2.6800e-06, 3.3091e-02, 3.1972e-06, 2.6873e-11, 1.1967e-05,\n 1.1480e-07, 3.3320e-09]) | 0.6461981534957886 |
| 6 | bottle;cow;person | chair;person;sofa | tensor([5.4520e-04, 4.2805e-03, 2.3828e-03, 1.4127e-03, 4.5856e-02, 3.5540e-03,\n 9.1525e-03, 2.9113e-02, 6.9326e-01, 1.0407e-03, 7.0658e-02, 3.1101e-02,\n 2.4843e-03, 2.9908e-03, 8.8695e-01, 2.2719e-01, 1.0283e-03, 6.0414e-01,\n 1.3598e-03, 5.7382e-02]) | 0.6329519152641296 |
| 7 | chair;dog;person | cat | tensor([3.4073e-05, 1.3574e-03, 7.0516e-04, 1.9189e-04, 6.0819e-03, 4.7242e-05,\n 9.6424e-04, 9.3669e-01, 9.0736e-02, 8.1472e-04, 1.1019e-02, 5.4633e-02,\n 2.6190e-04, 1.4943e-04, 1.2755e-02, 1.7530e-02, 2.2532e-03, 2.2129e-02,\n 1.5532e-04, 6.6390e-03]) | 0.6249645352363586 |
| 8 | car;person;pottedplant | car | tensor([1.3978e-06, 2.1693e-03, 2.2698e-07, 7.5037e-05, 9.4007e-07, 1.2369e-03,\n 9.9919e-01, 1.0879e-07, 3.1837e-04, 1.8340e-05, 7.5422e-06, 2.3891e-05,\n 2.5957e-05, 3.0890e-05, 8.4529e-02, 2.0280e-04, 4.1234e-09, 1.7978e-04,\n 2.3258e-05, 6.0897e-07]) | 0.5489450693130493 |

Multi-label classification - With the data block API
We can also use the data block API to get our data in a DataLoaders. Like we said before, feel free to skip this part if you are not comfortable with learning new APIs just yet.
Remember how the data is structured in our dataframe:
df.head()| fname | labels | is_valid | |
|---|---|---|---|
| 0 | 000005.jpg | chair | True |
| 1 | 000007.jpg | car | True |
| 2 | 000009.jpg | horse person | True |
| 3 | 000012.jpg | car | False |
| 4 | 000016.jpg | bicycle | True |
In this case we build the data block by providing:
- the types used:
ImageBlockandMultiCategoryBlock. - how to get the input items from our dataframe: here we read the column
fnameand need to add path/train/ at the beginning to get proper filenames. - how to get the targets from our dataframe: here we read the column
labelsand need to split by space. - how to split the items, here by using the column
is_valid. - the
item_tfmsandbatch_tfmslike before.
pascal = DataBlock(blocks=(ImageBlock, MultiCategoryBlock),
splitter=ColSplitter('is_valid'),
get_x=ColReader('fname', pref=str(path/'train') + os.path.sep),
get_y=ColReader('labels', label_delim=' '),
item_tfms = Resize(460),
batch_tfms=aug_transforms(size=224))This block is slightly different than before: we don’t need to pass a function to gather all our items as the dataframe we will give already has them all. However, we do need to preprocess the row of that dataframe to get out inputs, which is why we pass a get_x. It defaults to the fastai function noop, which is why we didn’t need to pass it along before.
Like before, pascal is just a blueprint. We need to pass it the source of our data to be able to get DataLoaders:
dls = pascal.dataloaders(df)Then we can look at some of our pictures with dls.show_batch()
dls.show_batch(max_n=9)
Segmentation
Segmentation is a problem where we have to predict a category for each pixel of the image. For this task, we will use the Camvid dataset, a dataset of screenshots from cameras in cars. Each pixel of the image has a label such as “road”, “car” or “pedestrian”.
As usual, we can download the data with our untar_data function.
path = untar_data(URLs.CAMVID_TINY)
path.ls()(#3) [Path('/home/jhoward/.fastai/data/camvid_tiny/codes.txt'),Path('/home/jhoward/.fastai/data/camvid_tiny/images'),Path('/home/jhoward/.fastai/data/camvid_tiny/labels')]The images folder contains the images, and the corresponding segmentation masks of labels are in the labels folder. The codes file contains the corresponding integer to class (the masks have an int value for each pixel).
codes = np.loadtxt(path/'codes.txt', dtype=str)
codesarray(['Animal', 'Archway', 'Bicyclist', 'Bridge', 'Building', 'Car',
'CartLuggagePram', 'Child', 'Column_Pole', 'Fence', 'LaneMkgsDriv',
'LaneMkgsNonDriv', 'Misc_Text', 'MotorcycleScooter', 'OtherMoving',
'ParkingBlock', 'Pedestrian', 'Road', 'RoadShoulder', 'Sidewalk',
'SignSymbol', 'Sky', 'SUVPickupTruck', 'TrafficCone',
'TrafficLight', 'Train', 'Tree', 'Truck_Bus', 'Tunnel',
'VegetationMisc', 'Void', 'Wall'], dtype='<U17')Segmentation - Using the high-level API
As before, the get_image_files function helps us grab all the image filenames:
fnames = get_image_files(path/"images")
fnames[0]Path('/home/jhoward/.fastai/data/camvid_tiny/images/0006R0_f02910.png')Let’s have a look in the labels folder:
(path/"labels").ls()[0]Path('/home/jhoward/.fastai/data/camvid_tiny/labels/0016E5_08137_P.png')It seems the segmentation masks have the same base names as the images but with an extra _P, so we can define a label function:
def label_func(fn): return path/"labels"/f"{fn.stem}_P{fn.suffix}"We can then gather our data using SegmentationDataLoaders:
dls = SegmentationDataLoaders.from_label_func(
path, bs=8, fnames = fnames, label_func = label_func, codes = codes
)We do not need to pass item_tfms to resize our images here because they already are all of the same size.
As usual, we can have a look at our data with the show_batch method. In this instance, the fastai library is superimposing the masks with one specific color per pixel:
dls.show_batch(max_n=6)
A traditional CNN won’t work for segmentation, we have to use a special kind of model called a UNet, so we use unet_learner to define our Learner:
learn = unet_learner(dls, resnet34)
learn.fine_tune(6)| epoch | train_loss | valid_loss | time |
|---|---|---|---|
| 0 | 2.802264 | 2.476579 | 00:03 |
| epoch | train_loss | valid_loss | time |
|---|---|---|---|
| 0 | 1.664625 | 1.525224 | 00:03 |
| 1 | 1.440311 | 1.271917 | 00:02 |
| 2 | 1.339473 | 1.123384 | 00:03 |
| 3 | 1.233049 | 0.988725 | 00:03 |
| 4 | 1.110815 | 0.805028 | 00:02 |
| 5 | 1.008600 | 0.815411 | 00:03 |
| 6 | 0.924937 | 0.755052 | 00:02 |
| 7 | 0.857789 | 0.769288 | 00:03 |
And as before, we can get some idea of the predicted results with show_results
learn.show_results(max_n=6, figsize=(7,8))
We can also sort the model’s errors on the validation set using the SegmentationInterpretation class and then plot the instances with the k highest contributions to the validation loss.
interp = SegmentationInterpretation.from_learner(learn)
interp.plot_top_losses(k=3)
Segmentation - With the data block API
We can also use the data block API to get our data in a DataLoaders. Like it’s been said before, feel free to skip this part if you are not comfortable with learning new APIs just yet.
In this case we build the data block by providing:
- the types used:
ImageBlockandMaskBlock. We provide thecodestoMaskBlockas there is no way to guess them from the data. - how to gather our items, here by using
get_image_files. - how to get the targets from our items: by using
label_func. - how to split the items, here randomly.
batch_tfmsfor data augmentation.
camvid = DataBlock(blocks=(ImageBlock, MaskBlock(codes)),
get_items = get_image_files,
get_y = label_func,
splitter=RandomSplitter(),
batch_tfms=aug_transforms(size=(120,160)))dls = camvid.dataloaders(path/"images", path=path, bs=8)dls.show_batch(max_n=6)
Points
This section uses the data block API, so if you skipped it before, we recommend you skip this section as well.
We will now look at a task where we want to predict points in a picture. For this, we will use the Biwi Kinect Head Pose Dataset. First thing first, let’s begin by downloading the dataset as usual.
path = untar_data(URLs.BIWI_HEAD_POSE)Let’s see what we’ve got!
path.ls()(#50) [Path('/home/sgugger/.fastai/data/biwi_head_pose/01.obj'),Path('/home/sgugger/.fastai/data/biwi_head_pose/18.obj'),Path('/home/sgugger/.fastai/data/biwi_head_pose/04'),Path('/home/sgugger/.fastai/data/biwi_head_pose/10.obj'),Path('/home/sgugger/.fastai/data/biwi_head_pose/24'),Path('/home/sgugger/.fastai/data/biwi_head_pose/14.obj'),Path('/home/sgugger/.fastai/data/biwi_head_pose/20.obj'),Path('/home/sgugger/.fastai/data/biwi_head_pose/11.obj'),Path('/home/sgugger/.fastai/data/biwi_head_pose/02.obj'),Path('/home/sgugger/.fastai/data/biwi_head_pose/07')...]There are 24 directories numbered from 01 to 24 (they correspond to the different persons photographed) and a corresponding .obj file (we won’t need them here). We’ll take a look inside one of these directories:
(path/'01').ls()(#1000) [Path('01/frame_00087_pose.txt'),Path('01/frame_00079_pose.txt'),Path('01/frame_00114_pose.txt'),Path('01/frame_00084_rgb.jpg'),Path('01/frame_00433_pose.txt'),Path('01/frame_00323_rgb.jpg'),Path('01/frame_00428_rgb.jpg'),Path('01/frame_00373_pose.txt'),Path('01/frame_00188_rgb.jpg'),Path('01/frame_00354_rgb.jpg')...]Inside the subdirectories, we have different frames, each of them come with an image (\_rgb.jpg) and a pose file (\_pose.txt). We can easily get all the image files recursively with get_image_files, then write a function that converts an image filename to its associated pose file.
img_files = get_image_files(path)
def img2pose(x): return Path(f'{str(x)[:-7]}pose.txt')
img2pose(img_files[0])Path('04/frame_00084_pose.txt')We can have a look at our first image:
im = PILImage.create(img_files[0])
im.shape(480, 640)im.to_thumb(160)
The Biwi dataset web site explains the format of the pose text file associated with each image, which shows the location of the center of the head. The details of this aren’t important for our purposes, so we’ll just show the function we use to extract the head center point:
cal = np.genfromtxt(path/'01'/'rgb.cal', skip_footer=6)
def get_ctr(f):
ctr = np.genfromtxt(img2pose(f), skip_header=3)
c1 = ctr[0] * cal[0][0]/ctr[2] + cal[0][2]
c2 = ctr[1] * cal[1][1]/ctr[2] + cal[1][2]
return tensor([c1,c2])This function returns the coordinates as a tensor of two items:
get_ctr(img_files[0])tensor([372.4046, 245.8602])We can pass this function to DataBlock as get_y, since it is responsible for labeling each item. We’ll resize the images to half their input size, just to speed up training a bit.
One important point to note is that we should not just use a random splitter. The reason for this is that the same person appears in multiple images in this dataset — but we want to ensure that our model can generalise to people that it hasn’t seen yet. Each folder in the dataset contains the images for one person. Therefore, we can create a splitter function which returns true for just one person, resulting in a validation set containing just that person’s images.
The only other difference to previous data block examples is that the second block is a PointBlock. This is necessary so that fastai knows that the labels represent coordinates; that way, it knows that when doing data augmentation, it should do the same augmentation to these coordinates as it does to the images.
biwi = DataBlock(
blocks=(ImageBlock, PointBlock),
get_items=get_image_files,
get_y=get_ctr,
splitter=FuncSplitter(lambda o: o.parent.name=='13'),
batch_tfms=[*aug_transforms(size=(240,320)),
Normalize.from_stats(*imagenet_stats)]
)dls = biwi.dataloaders(path)
dls.show_batch(max_n=9, figsize=(8,6))
Now that we have assembled our data, we can use the rest of the fastai API as usual. vision_learner works perfectly in this case, and the library will infer the proper loss function from the data:
learn = vision_learner(dls, resnet18, y_range=(-1,1))learn.lr_find()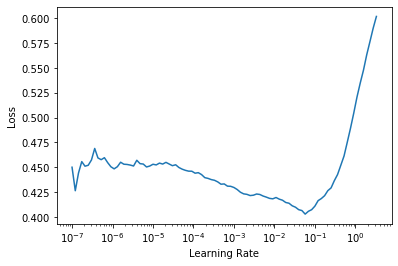
Then we can train our model:
learn.fine_tune(1, 5e-3)| epoch | train_loss | valid_loss | time |
|---|---|---|---|
| 0 | 0.057434 | 0.002171 | 00:31 |
| epoch | train_loss | valid_loss | time |
|---|---|---|---|
| 0 | 0.005320 | 0.005426 | 00:39 |
| 1 | 0.003624 | 0.000698 | 00:39 |
| 2 | 0.002163 | 0.000099 | 00:39 |
| 3 | 0.001325 | 0.000233 | 00:39 |
The loss is the mean squared error, so that means we make on average an error of
math.sqrt(0.0001)0.01percent when predicting our points! And we can look at those results as usual:
learn.show_results()