from PIL import ImageTorch Core
Basic pytorch functions used in the fastai library
setup_cuda
def setup_cuda(
benchmark:bool=True
):Sets the main cuda device and sets cudnn.benchmark to benchmark
Arrays and show
subplots
def subplots(
nrows:int=1, # Number of rows in returned axes grid
ncols:int=1, # Number of columns in returned axes grid
figsize:tuple=None, # Width, height in inches of the returned figure
imsize:int=3, # Size (in inches) of images that will be displayed in the returned figure
suptitle:str=None, # Title to be set to returned figure
sharex:bool | Literal['none', 'all', 'row', 'col']=False,
sharey:bool | Literal['none', 'all', 'row', 'col']=False, squeeze:bool=True,
width_ratios:Sequence[float] | None=None, height_ratios:Sequence[float] | None=None,
subplot_kw:dict[str, Any] | None=None, gridspec_kw:dict[str, Any] | None=None, **kwargs
)->(<class 'matplotlib.figure.Figure'>, <class 'matplotlib.axes._axes.Axes'>): # Returns both fig and ax as a tupleReturns a figure and set of subplots to display images of imsize inches
This is used in get_grid. suptitle, sharex, sharey, squeeze, subplot_kw and gridspec_kw are all passed down to plt.subplots.
show_image
def show_image(
im, ax:NoneType=None, figsize:NoneType=None, title:NoneType=None, ctx:NoneType=None, cmap:NoneType=None,
norm:NoneType=None, aspect:NoneType=None, interpolation:NoneType=None, alpha:NoneType=None, vmin:NoneType=None,
vmax:NoneType=None, colorizer:NoneType=None, origin:NoneType=None, extent:NoneType=None,
interpolation_stage:NoneType=None, filternorm:bool=True, filterrad:float=4.0, resample:NoneType=None,
url:NoneType=None, data:NoneType=None, **kwargs
):Show a PIL or PyTorch image on ax.
show_image can show PIL images…
im = Image.open(TEST_IMAGE_BW)
ax = show_image(im, cmap="Greys")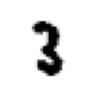
…and color images with standard CHW dim order…
im2 = np.array(Image.open(TEST_IMAGE))
ax = show_image(im2, figsize=(2,2))
…and color images with HWC dim order…
im3 = torch.as_tensor(im2).permute(2,0,1)
ax = show_image(im3, figsize=(2,2))
show_titled_image
def show_titled_image(
o, ax:NoneType=None, figsize:NoneType=None, title:NoneType=None, ctx:NoneType=None, cmap:NoneType=None,
norm:NoneType=None, aspect:NoneType=None, interpolation:NoneType=None, alpha:NoneType=None, vmin:NoneType=None,
vmax:NoneType=None, colorizer:NoneType=None, origin:NoneType=None, extent:NoneType=None,
interpolation_stage:NoneType=None, filternorm:bool=True, filterrad:float=4.0, resample:NoneType=None,
url:NoneType=None, data:NoneType=None, **kwargs
):Call show_image destructuring o to (img,title)
show_titled_image((im3,'A puppy'), figsize=(2,2))
Show all images ims as subplots with rows using titles. suptitle provides a way to create a figure title for all images. If you use suptitle, constrained_layout is used unless you set constrained_layout to False.
show_images
def show_images(
ims, nrows:int=1, # Number of rows in returned axes grid
ncols:NoneType=None, # Number of columns in returned axes grid
titles:NoneType=None, figsize:tuple=None, # Width, height in inches of the returned figure
imsize:int=3, # Size (in inches) of images that will be displayed in the returned figure
suptitle:str=None, # Title to be set to returned figure
sharex:bool | Literal['none', 'all', 'row', 'col']=False,
sharey:bool | Literal['none', 'all', 'row', 'col']=False, squeeze:bool=True,
width_ratios:Sequence[float] | None=None, height_ratios:Sequence[float] | None=None,
subplot_kw:dict[str, Any] | None=None, gridspec_kw:dict[str, Any] | None=None
): # Returns both fig and ax as a tupleShow all images ims as subplots with rows using titles.
show_images((im,im3),titles=('number','puppy'),suptitle='Number Puppy', imsize=3)
ArrayImage, ArrayImageBW and ArrayMask are subclasses of ndarray that know how to show themselves.
ArrayBase
def ArrayBase(
*args, **kwargs
):An ndarray that can modify casting behavior
ArrayImageBase
def ArrayImageBase(
*args, **kwargs
):Base class for arrays representing images
ArrayImage
def ArrayImage(
*args, **kwargs
):An array representing an image
ArrayImageBW
def ArrayImageBW(
*args, **kwargs
):An array representing an image
ArrayMask
def ArrayMask(
*args, **kwargs
):An array representing an image mask
im = Image.open(TEST_IMAGE)im_t = cast(im, ArrayImage)
test_eq(type(im_t), ArrayImage)ax = im_t.show(figsize=(2,2))
test_fig_exists(ax)Basics
Tensor.__array_eq__
def __array_eq__(
b
):Call self as a function.
tensor
def tensor(
x, *rest, dtype:NoneType=None, device:NoneType=None, requires_grad:bool=False, pin_memory:bool=False
):Like torch.as_tensor, but handle lists too, and can pass multiple vector elements directly.
test_eq(tensor(torch.tensor([1,2,3])), torch.tensor([1,2,3]))
test_eq(tensor(array([1,2,3])), torch.tensor([1,2,3]))
test_eq(tensor(1,2,3), torch.tensor([1,2,3]))
test_eq_type(tensor(1.0), torch.tensor(1.0))set_seed is useful for reproducibility between runs. It is important to remember that certain classes such as Dataloaders have internal random number generators that is not effected by this function, so this must be run before such objects are created in order to guarantee reproducibility.
set_seed
def set_seed(
s, reproducible:bool=False
):Set random seed for random, torch, and numpy (where available)
Here is an example of how set_seed can be used to reset the state of random number generators.
set_seed(2*33)
a1 = np.random.random()
a2 = torch.rand(())
a3 = random.random()
set_seed(2*33)
b1 = np.random.random()
b2 = torch.rand(())
b3 = random.random()
print('a\'s: {0:3.3f} {1:3.3f} {2:3.3f}'.format(a1,a2,a3))
print('b\'s: {0:3.3f} {1:3.3f} {2:3.3f}'.format(b1,b2,a3))a's: 0.154 0.498 0.071
b's: 0.154 0.498 0.071test_eq(a1,b1)
test_eq(a2,b2)
test_eq(a3,b3)get_random_states and set_random_states are useful for storing a state so you can go back to it later.
get_random_states
def get_random_states():Gets states for random, torch, and numpy random number generators
set_random_states
def set_random_states(
random_state, numpy_state, torch_state, torch_cuda_state, torch_deterministic, torch_benchmark
):Set states for random, torch, and numpy random number generators
Below notice that the old values and rewinded values are the same because we were able to return to the previous state.
old_states = get_random_states()
olds = (random.random(),np.random.random(),torch.rand(()))
news = (random.random(),np.random.random(),torch.rand(()))
set_random_states(**old_states)
rewinds = (random.random(),np.random.random(),torch.rand(()))
print('olds: {0:3.3f} {1:3.3f} {2:3.3f}'.format(*olds))
print('news: {0:3.3f} {1:3.3f} {2:3.3f}'.format(*news))
print('rewinds: {0:3.3f} {1:3.3f} {2:3.3f}'.format(*rewinds))olds: 0.435 0.134 0.023
news: 0.246 0.363 0.227
rewinds: 0.435 0.134 0.023test_ne(olds,news)
test_eq(olds,rewinds)In no_random we combine the ideas of rewinding state with get_random_states and set_random_states with the ability to set_seed and create a context manager that can allow us to control randomness in a portion of our code.
Note: Similar to torch.random.fork_rng, but also with numpy and random
no_random
def no_random(
seed:int=42, reproducible:bool=True
):Stores and retrieves state of random number generators. Sets random seed for random, torch, and numpy.
Here are some examples on how we can use no_random to control the randomness within a block of code.
states=get_random_states()
olds = (random.random(),np.random.random(),torch.rand(()))
set_random_states(**states) #rewinding above random calls
with no_random():
new1 = (random.random(),np.random.random(),torch.rand(()))
with no_random():
new2 = (random.random(),np.random.random(),torch.rand(()))
with no_random(seed=100):
seeded1 = (random.random(),np.random.random(),torch.rand(()))
with no_random(seed=100):
seeded2 = (random.random(),np.random.random(),torch.rand(()))
rewinds = (random.random(),np.random.random(),torch.rand(()))
print('olds: {0:3.3f} {1:3.3f} {2:3.3f}'.format(*olds))
print('new1: {0:3.3f} {1:3.3f} {2:3.3f}'.format(*new1))
print('new2: {0:3.3f} {1:3.3f} {2:3.3f}'.format(*new2))
print('seeded1: {0:3.3f} {1:3.3f} {2:3.3f}'.format(*seeded1))
print('seeded2: {0:3.3f} {1:3.3f} {2:3.3f}'.format(*seeded2))
print('rewinds: {0:3.3f} {1:3.3f} {2:3.3f}'.format(*rewinds))olds: 0.246 0.363 0.227
new1: 0.639 0.375 0.882
new2: 0.639 0.375 0.882
seeded1: 0.146 0.543 0.112
seeded2: 0.146 0.543 0.112
rewinds: 0.246 0.363 0.227Notice that olds, and rewinds are alos both equal to each other. From this we can see that everything in the with blocks did not update the state outside of the block. Inside of the block, the state is reset for any particular seed, so for the same seed you should get the same random number generator results.
Note: It is important to remember that classes like Dataloader have internal random number generators, and no_random will have no effect on those random number generators.
test_ne(olds,new1)
test_eq(new1,new2)
test_ne(new1,seeded1)
test_eq(seeded1,seeded2)
test_eq(olds,rewinds)unsqueeze
def unsqueeze(
x, dim:int=-1, n:int=1
):Same as torch.unsqueeze but can add n dims
t = tensor([1])
t2 = unsqueeze(t, n=2)
test_eq(t2,t[:,None,None])unsqueeze_
def unsqueeze_(
x, dim:int=-1, n:int=1
):Same as torch.unsqueeze_ but can add n dims
t = tensor([1])
unsqueeze_(t, n=2)
test_eq(t, tensor([1]).view(1,1,1))apply
def apply(
func, x, *args, **kwargs
):Apply func recursively to x, passing on args
maybe_gather
def maybe_gather(
x, axis:int=0
):Gather copies of x on axis (if training is distributed)
to_detach
def to_detach(
b, cpu:bool=True, gather:bool=True
):Recursively detach lists of tensors in b; put them on the CPU if cpu=True.
gather only applies during distributed training and the result tensor will be the one gathered across processes if gather=True (as a result, the batch size will be multiplied by the number of processes).
to_half
def to_half(
b
):Recursively map floating point tensors in b to FP16.
to_float
def to_float(
b
):Recursively map floating point tensors in b to float.
default_device
def default_device(
use:int=-1
):Return or set default device; use_cuda: -1 - CUDA/mps if available; True - error if not available; False - CPU
if torch.cuda.is_available():
_td = torch.device(torch.cuda.current_device())
test_eq(default_device(-1), _td)
test_eq(default_device(True), _td)
else:
test_eq(default_device(False), torch.device('cpu'))
default_device(-1);to_device
def to_device(
b, device:NoneType=None, non_blocking:bool=False
):Recursively put b on device.
t = to_device((3,(tensor(3),tensor(2))))
t1,(t2,t3) = tif torch.cuda.is_available():
test_eq_type(t,(3,(tensor(3).cuda(),tensor(2).cuda())))
test_eq(t2.type(), "torch.cuda.LongTensor")
test_eq(t3.type(), "torch.cuda.LongTensor")to_cpu
def to_cpu(
b
):Recursively map tensors in b to the cpu.
t3 = to_cpu(t3)
test_eq(t3.type(), "torch.LongTensor")
test_eq(t3, 2)to_np
def to_np(
x
):Convert a tensor to a numpy array.
t3 = to_np(t3)
test_eq(type(t3), np.ndarray)
test_eq(t3, 2)to_concat
def to_concat(
xs, dim:int=0
):Concat the element in xs (recursively if they are tuples/lists of tensors)
test_eq(to_concat([tensor([1,2]), tensor([3,4])]), tensor([1,2,3,4]))
test_eq(to_concat([tensor([[1,2]]), tensor([[3,4]])], dim=1), tensor([[1,2,3,4]]))
test_eq_type(to_concat([(tensor([1,2]), tensor([3,4])), (tensor([3,4]), tensor([5,6]))]), (tensor([1,2,3,4]), tensor([3,4,5,6])))
test_eq_type(to_concat([[tensor([1,2]), tensor([3,4])], [tensor([3,4]), tensor([5,6])]]), [tensor([1,2,3,4]), tensor([3,4,5,6])])
test_eq_type(to_concat([(tensor([1,2]),), (tensor([3,4]),)]), (tensor([1,2,3,4]),))
test_eq(to_concat([tensor([[1,2]]), tensor([[3,4], [5,6]])], dim=1), [tensor([1]),tensor([3, 5]),tensor([4, 6])])test_eq(type(to_concat([dict(foo=tensor([1,2]), bar=tensor(3,4))])), dict)Tensor subtypes
Tensor.set_meta
def set_meta(
x, as_copy:bool=False
):Set all metadata in __dict__
Tensor.as_subclass
def as_subclass(
typ
):Cast to typ and include __dict__ and meta
Tensor.set_meta and Tensor.as_subclass work together to maintain __dict__ after casting.
class _T(Tensor): pass
t = tensor(1.).requires_grad_()
t.img_size = 1
t2 = t.as_subclass(_T)
test_eq(t.img_size, t2.img_size)
test_eq(t2.img_size, 1)
assert(t2.requires_grad_)TensorBase
def TensorBase(
*args, **kwargs
):A Tensor which support subclass pickling, and maintains metadata when casting or after methods
TensorBase hooks into __torch_function__ to ensure metadata is not lost. To see all functions being called, set debug.
a = TensorBase(1)
TensorBase.debug=True
1/(a+1)<method 'add' of 'torch._C.TensorBase' objects> (<class '__main__.TensorBase'>,) (TensorBase(1), 1) None
<function Tensor.__rdiv__> (<class '__main__.TensorBase'>,) (TensorBase(2), 1) {}TensorBase(0.5000)TensorBase and its subclasses also allow for passing through metadata size as img_size…
from torch.utils.data._utils.collate import default_collatea = TensorBase(1,img_size=(128,128))
test_eq(a.img_size,(128,128))
b = cast(a,TensorBase)
test_eq(b.img_size,(128,128))
test_eq(torch.stack([a,b],0).img_size,(128,128))
test_eq(default_collate([a,b]).img_size,(128,128))<method-wrapper '__get__' of getset_descriptor object> (<class '__main__.TensorBase'>,) (TensorBase(1),) None
<built-in method stack of type object> (<class '__main__.TensorBase'>,) ([TensorBase(1), TensorBase(1)], 0) None
<method-wrapper '__get__' of getset_descriptor object> (<class '__main__.TensorBase'>,) (TensorBase(1),) None
<method-wrapper '__get__' of getset_descriptor object> (<class '__main__.TensorBase'>,) (TensorBase(1),) None
<built-in method stack of type object> (<class '__main__.TensorBase'>,) ([TensorBase(1), TensorBase(1)], 0) {'out': None}class _TImage(TensorBase): pass
class _TImage2(_TImage): pass
t1 = _TImage([1.])
t2 = _TImage2([1.])
t2+t1<method 'add' of 'torch._C.TensorBase' objects> (<class '__main__._TImage2'>, <class '__main__._TImage'>) (_TImage2([1.]), _TImage([1.])) None_TImage2([2.])class _T(TensorBase): pass
t = _T(range(5))
test_eq(t[0], 0)
test_eq_type(t+1, _T(range(1,6)))
test_eq(repr(t), '_T([0, 1, 2, 3, 4])')
test_eq_type(t[_T([False,False,True,True,True])], _T([2,3,4]))
test_eq_type(t[_T([2,3,4])], _T([2,3,4]))
test_eq(type(pickle.loads(pickle.dumps(t))), _T)
test_eq_type(t.new_ones(1), _T([1]))
test_eq_type(t.new_tensor([1,2]), _T([1,2]))<slot wrapper '__getitem__' of 'torch._C.TensorBase' objects> (<class '__main__._T'>,) (_T([0, 1, 2, 3, 4]), 0) None
<method 'dim' of 'torch._C.TensorBase' objects> (<class '__main__._T'>,) (_T(0),) None
<method '__eq__' of 'torch._C.TensorBase' objects> (<class '__main__._T'>,) (_T(0), 0) None
<method '__bool__' of 'torch._C.TensorBase' objects> (<class '__main__._T'>,) (_T(True),) None
<method 'add' of 'torch._C.TensorBase' objects> (<class '__main__._T'>,) (_T([0, 1, 2, 3, 4]), 1) None
<method 'dim' of 'torch._C.TensorBase' objects> (<class '__main__._T'>,) (_T([1, 2, 3, 4, 5]),) None
<built-in method equal of type object> (<class '__main__._T'>,) (_T([1, 2, 3, 4, 5]), _T([1, 2, 3, 4, 5])) None
<slot wrapper '__getitem__' of 'torch._C.TensorBase' objects> (<class '__main__._T'>,) (_T([0, 1, 2, 3, 4]), _T([False, False, True, True, True])) None
<method 'dim' of 'torch._C.TensorBase' objects> (<class '__main__._T'>,) (_T([2, 3, 4]),) None
<built-in method equal of type object> (<class '__main__._T'>,) (_T([2, 3, 4]), _T([2, 3, 4])) None
<slot wrapper '__getitem__' of 'torch._C.TensorBase' objects> (<class '__main__._T'>,) (_T([0, 1, 2, 3, 4]), _T([2, 3, 4])) None
<method 'dim' of 'torch._C.TensorBase' objects> (<class '__main__._T'>,) (_T([2, 3, 4]),) None
<built-in method equal of type object> (<class '__main__._T'>,) (_T([2, 3, 4]), _T([2, 3, 4])) None
<function Tensor.__reduce_ex__> (<class '__main__._T'>,) (_T([0, 1, 2, 3, 4]), 4) {}
<method 'dim' of 'torch._C.TensorBase' objects> (<class '__main__._T'>,) (_T([1]),) None
<built-in method equal of type object> (<class '__main__._T'>,) (_T([1]), _T([1])) None
<method 'dim' of 'torch._C.TensorBase' objects> (<class '__main__._T'>,) (_T([1, 2]),) None
<built-in method equal of type object> (<class '__main__._T'>,) (_T([1, 2]), _T([1, 2])) Nonet = tensor([1,2,3])
m = TensorBase([False,True,True])
test_eq(t[m], tensor([2,3]))
t = tensor([[1,2,3],[1,2,3]])
m = cast(tensor([[False,True,True],
[False,True,True]]), TensorBase)
test_eq(t[m], tensor([2,3,2,3]))<slot wrapper '__getitem__' of 'torch._C.TensorBase' objects> (<class '__main__.TensorBase'>,) (tensor([1, 2, 3]), TensorBase([False, True, True])) None
<method 'dim' of 'torch._C.TensorBase' objects> (<class '__main__.TensorBase'>,) (TensorBase([2, 3]),) None
<built-in method equal of type object> (<class '__main__.TensorBase'>,) (TensorBase([2, 3]), tensor([2, 3])) None
<slot wrapper '__getitem__' of 'torch._C.TensorBase' objects> (<class '__main__.TensorBase'>,) (tensor([[1, 2, 3],
[1, 2, 3]]), TensorBase([[False, True, True],
[False, True, True]])) None
<method 'dim' of 'torch._C.TensorBase' objects> (<class '__main__.TensorBase'>,) (TensorBase([2, 3, 2, 3]),) None
<built-in method equal of type object> (<class '__main__.TensorBase'>,) (TensorBase([2, 3, 2, 3]), tensor([2, 3, 2, 3])) Nonet = tensor([[1,2,3],[1,2,3]])
t.img_size = 1
t2 = cast(t, TensorBase)
test_eq(t2.img_size, t.img_size)
x = retain_type(tensor([4,5,6]), t2)
test_eq(x.img_size, t.img_size)
t3 = TensorBase([[1,2,3],[1,2,3]], img_size=1)
test_eq(t3.img_size, t.img_size)
t4 = t2+1
t4.img_size = 2
test_eq(t2.img_size, 1)
test_eq(t4.img_size, 2)
# this will fail with `Tensor` but works with `TensorBase`
test_eq(pickle.loads(pickle.dumps(t2)).img_size, t2.img_size)<method 'add' of 'torch._C.TensorBase' objects> (<class '__main__.TensorBase'>,) (TensorBase([[1, 2, 3],
[1, 2, 3]]), 1) None
<function Tensor.__reduce_ex__> (<class '__main__.TensorBase'>,) (TensorBase([[1, 2, 3],
[1, 2, 3]]), 4) {}TensorImageBase
def TensorImageBase(
*args, **kwargs
):A Tensor which support subclass pickling, and maintains metadata when casting or after methods
TensorImage
def TensorImage(
*args, **kwargs
):A Tensor which support subclass pickling, and maintains metadata when casting or after methods
TensorImageBW
def TensorImageBW(
*args, **kwargs
):A Tensor which support subclass pickling, and maintains metadata when casting or after methods
TensorMask
def TensorMask(
*args, **kwargs
):A Tensor which support subclass pickling, and maintains metadata when casting or after methods
im = Image.open(TEST_IMAGE)
im_t = cast(array(im), TensorImage)
test_eq(type(im_t), TensorImage)im_t2 = cast(tensor(1), TensorMask)
test_eq(type(im_t2), TensorMask)
test_eq(im_t2, tensor(1))
ax = im_t.show(figsize=(2,2))
_ =(im_t == im_t2)<method 'dim' of 'torch._C.TensorBase' objects> (<class '__main__.TensorMask'>,) (TensorMask(1),) None
<method '__eq__' of 'torch._C.TensorBase' objects> (<class '__main__.TensorMask'>,) (TensorMask(1), tensor(1)) None
<method '__bool__' of 'torch._C.TensorBase' objects> (<class '__main__.TensorMask'>,) (TensorMask(True),) None
<method-wrapper '__get__' of getset_descriptor object> (<class '__main__.TensorImage'>,) (TensorImage([[[192, 191, 199],
[195, 194, 202],
[199, 198, 204],
...,
[140, 142, 154],
[146, 148, 160],
[152, 154, 166]],
[[193, 192, 200],
[195, 194, 202],
[198, 197, 203],
...,
[142, 144, 156],
[148, 150, 162],
[153, 155, 167]],
[[194, 193, 201],
[194, 193, 201],
[196, 195, 203],
...,
[146, 148, 160],
[151, 153, 165],
[155, 157, 169]],
...,
[[160, 160, 162],
[159, 159, 161],
[161, 161, 163],
...,
[201, 202, 207],
[207, 206, 212],
[209, 210, 215]],
[[158, 158, 160],
[158, 158, 160],
[161, 161, 163],
...,
[208, 208, 216],
[213, 213, 223],
[215, 215, 225]],
[[156, 156, 158],
[157, 157, 159],
[160, 160, 162],
...,
[214, 214, 222],
[218, 218, 228],
[219, 219, 229]]], dtype=torch.uint8),) None
<method-wrapper '__get__' of getset_descriptor object> (<class '__main__.TensorImage'>,) (TensorImage([[[192, 191, 199],
[195, 194, 202],
[199, 198, 204],
...,
[140, 142, 154],
[146, 148, 160],
[152, 154, 166]],
[[193, 192, 200],
[195, 194, 202],
[198, 197, 203],
...,
[142, 144, 156],
[148, 150, 162],
[153, 155, 167]],
[[194, 193, 201],
[194, 193, 201],
[196, 195, 203],
...,
[146, 148, 160],
[151, 153, 165],
[155, 157, 169]],
...,
[[160, 160, 162],
[159, 159, 161],
[161, 161, 163],
...,
[201, 202, 207],
[207, 206, 212],
[209, 210, 215]],
[[158, 158, 160],
[158, 158, 160],
[161, 161, 163],
...,
[208, 208, 216],
[213, 213, 223],
[215, 215, 225]],
[[156, 156, 158],
[157, 157, 159],
[160, 160, 162],
...,
[214, 214, 222],
[218, 218, 228],
[219, 219, 229]]], dtype=torch.uint8),) None
<method 'cpu' of 'torch._C.TensorBase' objects> (<class '__main__.TensorImage'>,) (TensorImage([[[192, 191, 199],
[195, 194, 202],
[199, 198, 204],
...,
[140, 142, 154],
[146, 148, 160],
[152, 154, 166]],
[[193, 192, 200],
[195, 194, 202],
[198, 197, 203],
...,
[142, 144, 156],
[148, 150, 162],
[153, 155, 167]],
[[194, 193, 201],
[194, 193, 201],
[196, 195, 203],
...,
[146, 148, 160],
[151, 153, 165],
[155, 157, 169]],
...,
[[160, 160, 162],
[159, 159, 161],
[161, 161, 163],
...,
[201, 202, 207],
[207, 206, 212],
[209, 210, 215]],
[[158, 158, 160],
[158, 158, 160],
[161, 161, 163],
...,
[208, 208, 216],
[213, 213, 223],
[215, 215, 225]],
[[156, 156, 158],
[157, 157, 159],
[160, 160, 162],
...,
[214, 214, 222],
[218, 218, 228],
[219, 219, 229]]], dtype=torch.uint8),) None
<method-wrapper '__get__' of getset_descriptor object> (<class '__main__.TensorImage'>,) (TensorImage([[[192, 191, 199],
[195, 194, 202],
[199, 198, 204],
...,
[140, 142, 154],
[146, 148, 160],
[152, 154, 166]],
[[193, 192, 200],
[195, 194, 202],
[198, 197, 203],
...,
[142, 144, 156],
[148, 150, 162],
[153, 155, 167]],
[[194, 193, 201],
[194, 193, 201],
[196, 195, 203],
...,
[146, 148, 160],
[151, 153, 165],
[155, 157, 169]],
...,
[[160, 160, 162],
[159, 159, 161],
[161, 161, 163],
...,
[201, 202, 207],
[207, 206, 212],
[209, 210, 215]],
[[158, 158, 160],
[158, 158, 160],
[161, 161, 163],
...,
[208, 208, 216],
[213, 213, 223],
[215, 215, 225]],
[[156, 156, 158],
[157, 157, 159],
[160, 160, 162],
...,
[214, 214, 222],
[218, 218, 228],
[219, 219, 229]]], dtype=torch.uint8),) None
<method-wrapper '__get__' of getset_descriptor object> (<class '__main__.TensorImage'>,) (TensorImage([[[192, 191, 199],
[195, 194, 202],
[199, 198, 204],
...,
[140, 142, 154],
[146, 148, 160],
[152, 154, 166]],
[[193, 192, 200],
[195, 194, 202],
[198, 197, 203],
...,
[142, 144, 156],
[148, 150, 162],
[153, 155, 167]],
[[194, 193, 201],
[194, 193, 201],
[196, 195, 203],
...,
[146, 148, 160],
[151, 153, 165],
[155, 157, 169]],
...,
[[160, 160, 162],
[159, 159, 161],
[161, 161, 163],
...,
[201, 202, 207],
[207, 206, 212],
[209, 210, 215]],
[[158, 158, 160],
[158, 158, 160],
[161, 161, 163],
...,
[208, 208, 216],
[213, 213, 223],
[215, 215, 225]],
[[156, 156, 158],
[157, 157, 159],
[160, 160, 162],
...,
[214, 214, 222],
[218, 218, 228],
[219, 219, 229]]], dtype=torch.uint8),) None
<function Tensor.__array__> (<class '__main__.TensorImage'>,) (TensorImage([[[192, 191, 199],
[195, 194, 202],
[199, 198, 204],
...,
[140, 142, 154],
[146, 148, 160],
[152, 154, 166]],
[[193, 192, 200],
[195, 194, 202],
[198, 197, 203],
...,
[142, 144, 156],
[148, 150, 162],
[153, 155, 167]],
[[194, 193, 201],
[194, 193, 201],
[196, 195, 203],
...,
[146, 148, 160],
[151, 153, 165],
[155, 157, 169]],
...,
[[160, 160, 162],
[159, 159, 161],
[161, 161, 163],
...,
[201, 202, 207],
[207, 206, 212],
[209, 210, 215]],
[[158, 158, 160],
[158, 158, 160],
[161, 161, 163],
...,
[208, 208, 216],
[213, 213, 223],
[215, 215, 225]],
[[156, 156, 158],
[157, 157, 159],
[160, 160, 162],
...,
[214, 214, 222],
[218, 218, 228],
[219, 219, 229]]], dtype=torch.uint8),) {'dtype': None}
<method '__eq__' of 'torch._C.TensorBase' objects> (<class '__main__.TensorImage'>,) (TensorImage([[[192, 191, 199],
[195, 194, 202],
[199, 198, 204],
...,
[140, 142, 154],
[146, 148, 160],
[152, 154, 166]],
[[193, 192, 200],
[195, 194, 202],
[198, 197, 203],
...,
[142, 144, 156],
[148, 150, 162],
[153, 155, 167]],
[[194, 193, 201],
[194, 193, 201],
[196, 195, 203],
...,
[146, 148, 160],
[151, 153, 165],
[155, 157, 169]],
...,
[[160, 160, 162],
[159, 159, 161],
[161, 161, 163],
...,
[201, 202, 207],
[207, 206, 212],
[209, 210, 215]],
[[158, 158, 160],
[158, 158, 160],
[161, 161, 163],
...,
[208, 208, 216],
[213, 213, 223],
[215, 215, 225]],
[[156, 156, 158],
[157, 157, 159],
[160, 160, 162],
...,
[214, 214, 222],
[218, 218, 228],
[219, 219, 229]]], dtype=torch.uint8), TensorMask(1)) None
test_fig_exists(ax)Operations between TensorMask and TensorImageBase objects return the type of the TensorImageBase object:
a = TensorMask([1,2])
test_eq_type(TensorImage(1)+a, TensorImage([2,3]))
test_eq_type(1-a, TensorMask([0,-1]))<method 'add' of 'torch._C.TensorBase' objects> (<class '__main__.TensorImage'>, <class '__main__.TensorMask'>) (TensorImage(1), TensorMask([1, 2])) None
<method 'dim' of 'torch._C.TensorBase' objects> (<class '__main__.TensorImage'>,) (TensorImage([2, 3]),) None
<built-in method equal of type object> (<class '__main__.TensorImage'>,) (TensorImage([2, 3]), TensorImage([2, 3])) None
<function Tensor.__rsub__> (<class '__main__.TensorMask'>,) (TensorMask([1, 2]), 1) {}
<method 'dim' of 'torch._C.TensorBase' objects> (<class '__main__.TensorMask'>,) (TensorMask([ 0, -1]),) None
<built-in method equal of type object> (<class '__main__.TensorMask'>,) (TensorMask([ 0, -1]), TensorMask([ 0, -1])) NoneTensorFlowField
def TensorFlowField(
*args, **kwargs
):A Tensor which support subclass pickling, and maintains metadata when casting or after methods
t1 = TensorImage([1.]).view(1,1,1,1)
t2 = TensorFlowField([1.,1.]).view(1,1,1,2)
test_eq_type(F.grid_sample(t1, t2), TensorImage([[[[0.25]]]]))<method 'view' of 'torch._C.TensorBase' objects> (<class '__main__.TensorImage'>,) (TensorImage([1.]), 1, 1, 1, 1) None
<method 'view' of 'torch._C.TensorBase' objects> (<class '__main__.TensorFlowField'>,) (TensorFlowField([1., 1.]), 1, 1, 1, 2) None
<function grid_sample> (<class '__main__.TensorImage'>, <class '__main__.TensorFlowField'>) (TensorImage([[[[1.]]]]), TensorFlowField([[[[1., 1.]]]])) {'mode': 'bilinear', 'padding_mode': 'zeros', 'align_corners': None}
<method 'dim' of 'torch._C.TensorBase' objects> (<class '__main__.TensorImage'>,) (TensorImage([[[[0.2500]]]]),) None
<built-in method equal of type object> (<class '__main__.TensorImage'>,) (TensorImage([[[[0.2500]]]]), TensorImage([[[[0.2500]]]])) NoneTensorCategory
def TensorCategory(
*args, **kwargs
):A Tensor which support subclass pickling, and maintains metadata when casting or after methods
tc = TensorCategory([1,2,3])
mask_t = TensorMask([0,2,4,5])
im_t = TensorImage([0,2,4,5])
test_eq(mask_t[tc], tensor([2,4,5]))
test_eq(im_t[tc], tensor([2,4,5]))<slot wrapper '__getitem__' of 'torch._C.TensorBase' objects> (<class '__main__.TensorMask'>, <class '__main__.TensorCategory'>) (TensorMask([0, 2, 4, 5]), TensorCategory([1, 2, 3])) None
<method 'dim' of 'torch._C.TensorBase' objects> (<class '__main__.TensorMask'>,) (TensorMask([2, 4, 5]),) None
<built-in method equal of type object> (<class '__main__.TensorMask'>,) (TensorMask([2, 4, 5]), tensor([2, 4, 5])) None
<slot wrapper '__getitem__' of 'torch._C.TensorBase' objects> (<class '__main__.TensorImage'>, <class '__main__.TensorCategory'>) (TensorImage([0, 2, 4, 5]), TensorCategory([1, 2, 3])) None
<method 'dim' of 'torch._C.TensorBase' objects> (<class '__main__.TensorImage'>,) (TensorImage([2, 4, 5]),) None
<built-in method equal of type object> (<class '__main__.TensorImage'>,) (TensorImage([2, 4, 5]), tensor([2, 4, 5])) NoneTensorMultiCategory
def TensorMultiCategory(
*args, **kwargs
):A Tensor which support subclass pickling, and maintains metadata when casting or after methods
TitledTensorScalar
def TitledTensorScalar(
*args, **kwargs
):A tensor containing a scalar that has a show method
L.cat
def cat(
dim:int=0
):Same as torch.cat
L.stack
def stack(
dim:int=0
):Same as torch.stack
L.tensored
def tensored():mapped(tensor)
L.tensored
def tensored():mapped(tensor)
There are shortcuts for torch.stack and torch.cat if your L contains tensors or something convertible. You can manually convert with tensored.
t = L(([1,2],[3,4]))
test_eq(t.tensored(), [tensor(1,2),tensor(3,4)])L.stack
def stack(
dim:int=0
):Same as torch.stack
test_eq(t.stack(), tensor([[1,2],[3,4]]))L.cat
def cat(
dim:int=0
):Same as torch.cat
test_eq(t.cat(), tensor([1,2,3,4]))Chunks
concat
def concat(
*ls
):Concatenate tensors, arrays, lists, or tuples
a,b,c = [1],[1,2],[1,1,2]
test_eq(concat(a,b), c)
test_eq_type(concat(tuple (a),tuple (b)), tuple (c))
test_eq_type(concat(array (a),array (b)), array (c))
test_eq_type(concat(tensor(a),tensor(b)), tensor(c))
test_eq_type(concat(TensorBase(a),TensorBase(b)), TensorBase(c))
test_eq_type(concat([1,1],1), [1,1,1])
test_eq_type(concat(1,1,1), L(1,1,1))
test_eq_type(concat(L(1,2),1), L(1,2,1))<built-in method cat of type object> (<class '__main__.TensorBase'>,) ((TensorBase([1]), TensorBase([1, 2])),) None
<method 'dim' of 'torch._C.TensorBase' objects> (<class '__main__.TensorBase'>,) (TensorBase([1, 1, 2]),) None
<built-in method equal of type object> (<class '__main__.TensorBase'>,) (TensorBase([1, 1, 2]), TensorBase([1, 1, 2])) NoneChunks
def Chunks(
chunks, lens:NoneType=None
):Slice and int indexing into a list of lists
docs = L(list(string.ascii_lowercase[a:b]) for a,b in ((0,3),(3,7),(7,8),(8,16),(16,24),(24,26)))
b = Chunks(docs)
test_eq([b[ o] for o in range(0,5)], ['a','b','c','d','e'])
test_eq([b[-o] for o in range(1,6)], ['z','y','x','w','v'])
test_eq(b[6:13], 'g,h,i,j,k,l,m'.split(','))
test_eq(b[20:77], 'u,v,w,x,y,z'.split(','))
test_eq(b[:5], 'a,b,c,d,e'.split(','))
test_eq(b[:2], 'a,b'.split(','))t = torch.arange(26)
docs = L(t[a:b] for a,b in ((0,3),(3,7),(7,8),(8,16),(16,24),(24,26)))
b = Chunks(docs)
test_eq([b[ o] for o in range(0,5)], range(0,5))
test_eq([b[-o] for o in range(1,6)], [25,24,23,22,21])
test_eq(b[6:13], torch.arange(6,13))
test_eq(b[20:77], torch.arange(20,26))
test_eq(b[:5], torch.arange(5))
test_eq(b[:2], torch.arange(2))docs = L(TensorBase(t[a:b]) for a,b in ((0,3),(3,7),(7,8),(8,16),(16,24),(24,26)))
b = Chunks(docs)
test_eq_type(b[:2], TensorBase(range(2)))
test_eq_type(b[:5], TensorBase(range(5)))
test_eq_type(b[9:13], TensorBase(range(9,13)))<function Tensor.__len__> (<class '__main__.TensorBase'>,) (TensorBase([0, 1, 2]),) {}
<function Tensor.__len__> (<class '__main__.TensorBase'>,) (TensorBase([3, 4, 5, 6]),) {}
<function Tensor.__len__> (<class '__main__.TensorBase'>,) (TensorBase([7]),) {}
<function Tensor.__len__> (<class '__main__.TensorBase'>,) (TensorBase([ 8, 9, 10, 11, 12, 13, 14, 15]),) {}
<function Tensor.__len__> (<class '__main__.TensorBase'>,) (TensorBase([16, 17, 18, 19, 20, 21, 22, 23]),) {}
<function Tensor.__len__> (<class '__main__.TensorBase'>,) (TensorBase([24, 25]),) {}
<slot wrapper '__getitem__' of 'torch._C.TensorBase' objects> (<class '__main__.TensorBase'>,) (TensorBase([0, 1, 2]), slice(0, 2, None)) None
<built-in method cat of type object> (<class '__main__.TensorBase'>,) ((TensorBase([0, 1]),),) None
<method 'dim' of 'torch._C.TensorBase' objects> (<class '__main__.TensorBase'>,) (TensorBase([0, 1]),) None
<built-in method equal of type object> (<class '__main__.TensorBase'>,) (TensorBase([0, 1]), TensorBase([0, 1])) None
<slot wrapper '__getitem__' of 'torch._C.TensorBase' objects> (<class '__main__.TensorBase'>,) (TensorBase([0, 1, 2]), slice(0, 9223372036854775807, None)) None
<slot wrapper '__getitem__' of 'torch._C.TensorBase' objects> (<class '__main__.TensorBase'>,) (TensorBase([3, 4, 5, 6]), slice(None, 2, None)) None
<built-in method cat of type object> (<class '__main__.TensorBase'>,) ((TensorBase([0, 1, 2]), TensorBase([3, 4])),) None
<method 'dim' of 'torch._C.TensorBase' objects> (<class '__main__.TensorBase'>,) (TensorBase([0, 1, 2, 3, 4]),) None
<built-in method equal of type object> (<class '__main__.TensorBase'>,) (TensorBase([0, 1, 2, 3, 4]), TensorBase([0, 1, 2, 3, 4])) None
<slot wrapper '__getitem__' of 'torch._C.TensorBase' objects> (<class '__main__.TensorBase'>,) (TensorBase([ 8, 9, 10, 11, 12, 13, 14, 15]), slice(1, 5, None)) None
<built-in method cat of type object> (<class '__main__.TensorBase'>,) ((TensorBase([ 9, 10, 11, 12]),),) None
<method 'dim' of 'torch._C.TensorBase' objects> (<class '__main__.TensorBase'>,) (TensorBase([ 9, 10, 11, 12]),) None
<built-in method equal of type object> (<class '__main__.TensorBase'>,) (TensorBase([ 9, 10, 11, 12]), TensorBase([ 9, 10, 11, 12])) NoneSimple types
show_title
def show_title(
o, ax:NoneType=None, ctx:NoneType=None, label:NoneType=None, color:str='black', **kwargs
):Set title of ax to o, or print o if ax is None
test_stdout(lambda: show_title("title"), "title")
# ensure that col names are unique when showing to a pandas series
assert show_title("title", ctx=pd.Series(dict(a=1)), label='a').equals(pd.Series(dict(a=1,a_='title')))ShowTitle
def ShowTitle(
*args, **kwargs
):Base class that adds a simple show
TitledInt
def TitledInt(
*args, **kwargs
):An int with show
TitledStr
def TitledStr(
*args, **kwargs
):An str with show
TitledFloat
def TitledFloat(
*args, **kwargs
):A float with show
test_stdout(lambda: TitledStr('s').show(), 's')
test_stdout(lambda: TitledInt(1).show(), '1')TitledTuple
def TitledTuple(
*args, **kwargs
):A fastuple with show
TitledStr.truncate
def truncate(
n
):Truncate self to n
Other functions
DataFrame.__init__
def __init__(
data:NoneType=None, index:NoneType=None, columns:NoneType=None, dtype:NoneType=None, copy:NoneType=None
):Call self as a function.
get_empty_df
def get_empty_df(
n
):Return n empty rows of a dataframe
display_df
def display_df(
df
):Display df in a notebook or defaults to print
get_first
def get_first(
c
):Get the first element of c, even if c is a dataframe
one_param
def one_param(
m
):First parameter in m
item_find
def item_find(
x, idx:int=0
):Recursively takes the idx-th element of x
find_device
def find_device(
b
):Recursively search the device of b.
t2 = to_device(tensor(0))
dev = default_device()
test_eq(find_device(t2), dev)
test_eq(find_device([t2,t2]), dev)
test_eq(find_device({'a':t2,'b':t2}), dev)
test_eq(find_device({'a':[[t2],[t2]],'b':t2}), dev)find_bs
def find_bs(
b
):Recursively search the batch size of b.
x = torch.randn(4,5)
x1 = [1,2,3]
test_eq(find_bs(x1), 3)
test_eq(find_bs(x), 4)
test_eq(find_bs((x,x)), 4)
test_eq(find_bs([x, x]), 4)
test_eq(find_bs({'a':x,'b':x}), 4)
test_eq(find_bs({'a':[[x],[x]],'b':x}), 4)np_func
def np_func(
f
):Convert a function taking and returning numpy arrays to one taking and returning tensors
This decorator is particularly useful for using numpy functions as fastai metrics, for instance:
from sklearn.metrics import f1_score@np_func
def f1(inp,targ): return f1_score(targ, inp)
a1,a2 = array([0,1,1]),array([1,0,1])
t = f1(tensor(a1),tensor(a2))
test_eq(f1_score(a1,a2), t)
assert isinstance(t,Tensor)Module
def Module():Same as nn.Module, but no need for subclasses to call super().__init__
class _T(Module):
def __init__(self): self.f = nn.Linear(1,1)
def forward(self,x): return self.f(x)
t = _T()
t(tensor([1.]))tensor([0.9937], grad_fn=<ViewBackward0>)get_model
def get_model(
model
):Return the model maybe wrapped inside model.
one_hot
def one_hot(
x, c
):One-hot encode x with c classes.
test_eq(one_hot([1,4], 5), tensor(0,1,0,0,1).byte())
test_eq(one_hot(torch.tensor([]), 5), tensor(0,0,0,0,0).byte())
test_eq(one_hot(2, 5), tensor(0,0,1,0,0).byte())one_hot_decode
def one_hot_decode(
x, vocab:NoneType=None
):Call self as a function.
test_eq(one_hot_decode(tensor(0,1,0,0,1)), [1,4])
test_eq(one_hot_decode(tensor(0,0,0,0,0)), [ ])
test_eq(one_hot_decode(tensor(0,0,1,0,0)), [2 ])params
def params(
m
):Return all parameters of m
trainable_params
def trainable_params(
m
):Return all trainable parameters of m
m = nn.Linear(4,5)
test_eq(trainable_params(m), [m.weight, m.bias])
m.weight.requires_grad_(False)
test_eq(trainable_params(m), [m.bias])norm_bias_params
def norm_bias_params(
m, with_bias:bool=True
):Return all bias and BatchNorm parameters
for norm_func in [nn.BatchNorm1d, partial(nn.InstanceNorm1d, affine=True)]:
model = nn.Sequential(nn.Linear(10,20), norm_func(20), nn.Conv1d(3,4, 3))
test_eq(norm_bias_params(model), [model[0].bias, model[1].weight, model[1].bias, model[2].bias])
model = nn.ModuleList([nn.Linear(10,20, bias=False), nn.Sequential(norm_func(20), nn.Conv1d(3,4,3))])
test_eq(norm_bias_params(model), [model[1][0].weight, model[1][0].bias, model[1][1].bias])
model = nn.ModuleList([nn.Linear(10,20), nn.Sequential(norm_func(20), nn.Conv1d(3,4,3))])
test_eq(norm_bias_params(model, with_bias=False), [model[1][0].weight, model[1][0].bias])batch_to_samples
def batch_to_samples(
b, max_n:int=10
):‘Transposes’ a batch to (at most max_n) samples
t = tensor([1,2,3])
test_eq(batch_to_samples([t,t+1], max_n=2), ([1,2],[2,3]))
test_eq(batch_to_samples(tensor([1,2,3]), 10), [1, 2, 3])
test_eq(batch_to_samples([tensor([1,2,3]), tensor([4,5,6])], 10), [(1, 4), (2, 5), (3, 6)])
test_eq(batch_to_samples([tensor([1,2,3]), tensor([4,5,6])], 2), [(1, 4), (2, 5)])
test_eq(batch_to_samples([tensor([1,2,3]), [tensor([4,5,6]),tensor([7,8,9])]], 10),
[(1, (4, 7)), (2, (5, 8)), (3, (6, 9))])
test_eq(batch_to_samples([tensor([1,2,3]), [tensor([4,5,6]),tensor([7,8,9])]], 2), [(1, (4, 7)), (2, (5, 8))])
t = fastuple(tensor([1,2,3]),TensorBase([2,3,4]))
test_eq_type(batch_to_samples(t)[0][1], TensorBase(2))
test_eq(batch_to_samples(t).map(type), [fastuple]*3)<slot wrapper '__getitem__' of 'torch._C.TensorBase' objects> (<class '__main__.TensorBase'>,) (TensorBase([2, 3, 4]), slice(None, 10, None)) None
<method 'dim' of 'torch._C.TensorBase' objects> (<class '__main__.TensorBase'>,) (TensorBase([2, 3, 4]),) None
<method 'unbind' of 'torch._C.TensorBase' objects> (<class '__main__.TensorBase'>,) (TensorBase([2, 3, 4]), 0) None
<function Tensor.__len__> (<class '__main__.TensorBase'>,) (TensorBase([2, 3, 4]),) {}
<method 'dim' of 'torch._C.TensorBase' objects> (<class '__main__.TensorBase'>,) (TensorBase(2),) None
<method '__eq__' of 'torch._C.TensorBase' objects> (<class '__main__.TensorBase'>,) (TensorBase(2), TensorBase(2)) None
<method '__bool__' of 'torch._C.TensorBase' objects> (<class '__main__.TensorBase'>,) (TensorBase(True),) None
<slot wrapper '__getitem__' of 'torch._C.TensorBase' objects> (<class '__main__.TensorBase'>,) (TensorBase([2, 3, 4]), slice(None, 10, None)) None
<method 'dim' of 'torch._C.TensorBase' objects> (<class '__main__.TensorBase'>,) (TensorBase([2, 3, 4]),) None
<method 'unbind' of 'torch._C.TensorBase' objects> (<class '__main__.TensorBase'>,) (TensorBase([2, 3, 4]), 0) None
<function Tensor.__len__> (<class '__main__.TensorBase'>,) (TensorBase([2, 3, 4]),) {}Tensor.interp_1d
def interp_1d(
x:Tensor, xp, fp
):Same as np.interp
brks = tensor(0,1,2,4,8,64).float()
ys = tensor(range_of(brks)).float()
ys /= ys[-1].item()
pts = tensor(0.2,0.5,0.8,3,5,63)
preds = pts.interp_1d(brks, ys)
test_close(preds.numpy(), np.interp(pts.numpy(), brks.numpy(), ys.numpy()))
plt.scatter(brks,ys)
plt.scatter(pts,preds)
plt.legend(['breaks','preds']);
Tensor.pca
def pca(
x:Tensor, k:int=2
):Compute PCA of x with k dimensions.
logit
def logit(
x
):Logit of x, clamped to avoid inf.
num_distrib
def num_distrib():Return the number of processes in distributed training (if applicable).
rank_distrib
def rank_distrib():Return the distributed rank of this process (if applicable).
distrib_barrier
def distrib_barrier():Place a synchronization barrier in distributed training
After calling this, ALL sub-processes in the pytorch process group must arrive here before proceeding.
Path.save_array
def save_array(
p:Path, o, complib:str='lz4', lvl:int=3
):Save numpy array to a compressed pytables file, using compression level lvl
Compression lib can be any of: blosclz, lz4, lz4hc, snappy, zlib or zstd.
Path.load_array
def load_array(
p:Path
):Save numpy array to a pytables file
base_doc
def base_doc(
elt
):Print a base documentation of elt
doc
def doc(
elt
):Try to use doc form nbdev and fall back to base_doc
nested_reorder
def nested_reorder(
t, idxs
):Reorder all tensors in t using idxs
x = tensor([0,1,2,3,4,5])
idxs = tensor([2,5,1,0,3,4])
test_eq_type(nested_reorder(([x], x), idxs), ([idxs], idxs))
y = L(0,1,2,3,4,5)
z = L(i.item() for i in idxs)
test_eq_type(nested_reorder((y, x), idxs), (z,idxs))flatten_check
def flatten_check(
inp, targ
):Check that inp and targ have the same number of elements and flatten them.
x1,x2 = torch.randn(5,4),torch.randn(20)
x1,x2 = flatten_check(x1,x2)
test_eq(x1.shape, [20])
test_eq(x2.shape, [20])
x1,x2 = torch.randn(5,4),torch.randn(21)
with expect_fail(): flatten_check(x1,x2)<method 'view' of 'torch._C.TensorBase' objects> (<class '__main__.TensorBase'>,) (TensorBase([[ 1.0382, 0.2694, 0.1557, 0.8046],
[ 0.2153, -0.8074, 1.3402, -0.5470],
[-0.9837, -1.5019, 1.0357, 0.1674],
[ 0.4258, 0.3218, 0.4773, -0.4644],
[-0.8298, -0.0215, -0.5018, 2.3215]]), -1) None
<method 'view' of 'torch._C.TensorBase' objects> (<class '__main__.TensorBase'>,) (TensorBase([ 2.8900, -1.3661, 0.1912, 0.5172, -1.3732, -0.5845, -0.7272,
-0.0853, -0.0387, 0.8470, 1.3114, -0.0933, -1.6411, -0.3346,
0.9161, 1.1654, 0.2641, -1.2561, 0.9964, 1.1314]), -1) None
<function Tensor.__len__> (<class '__main__.TensorBase'>,) (TensorBase([ 1.0382, 0.2694, 0.1557, 0.8046, 0.2153, -0.8074, 1.3402,
-0.5470, -0.9837, -1.5019, 1.0357, 0.1674, 0.4258, 0.3218,
0.4773, -0.4644, -0.8298, -0.0215, -0.5018, 2.3215]),) {}
<function Tensor.__len__> (<class '__main__.TensorBase'>,) (TensorBase([ 2.8900, -1.3661, 0.1912, 0.5172, -1.3732, -0.5845, -0.7272,
-0.0853, -0.0387, 0.8470, 1.3114, -0.0933, -1.6411, -0.3346,
0.9161, 1.1654, 0.2641, -1.2561, 0.9964, 1.1314]),) {}
<method-wrapper '__get__' of getset_descriptor object> (<class '__main__.TensorBase'>,) (TensorBase([ 1.0382, 0.2694, 0.1557, 0.8046, 0.2153, -0.8074, 1.3402,
-0.5470, -0.9837, -1.5019, 1.0357, 0.1674, 0.4258, 0.3218,
0.4773, -0.4644, -0.8298, -0.0215, -0.5018, 2.3215]),) None
<method-wrapper '__get__' of getset_descriptor object> (<class '__main__.TensorBase'>,) (TensorBase([ 2.8900, -1.3661, 0.1912, 0.5172, -1.3732, -0.5845, -0.7272,
-0.0853, -0.0387, 0.8470, 1.3114, -0.0933, -1.6411, -0.3346,
0.9161, 1.1654, 0.2641, -1.2561, 0.9964, 1.1314]),) None
<method 'view' of 'torch._C.TensorBase' objects> (<class '__main__.TensorBase'>,) (TensorBase([[-1.7181, -0.2147, -1.2145, -1.6510],
[ 0.3447, -1.0924, 0.1994, -0.0726],
[-0.5407, 0.0623, -0.0966, -0.0448],
[ 0.7951, -0.2282, -0.8035, 1.5779],
[-0.3452, 0.3078, 1.3254, -0.4378]]), -1) None
<method 'view' of 'torch._C.TensorBase' objects> (<class '__main__.TensorBase'>,) (TensorBase([-0.1303, 0.4928, -0.3458, -0.5185, 1.4189, 1.1956, -1.2492,
1.0312, -0.4071, 0.4928, 0.3276, -0.3133, -0.3452, -0.2146,
-0.9111, 0.2789, 0.4154, 1.4559, -1.5123, -1.3805, -0.3555]), -1) None
<function Tensor.__len__> (<class '__main__.TensorBase'>,) (TensorBase([-1.7181, -0.2147, -1.2145, -1.6510, 0.3447, -1.0924, 0.1994,
-0.0726, -0.5407, 0.0623, -0.0966, -0.0448, 0.7951, -0.2282,
-0.8035, 1.5779, -0.3452, 0.3078, 1.3254, -0.4378]),) {}
<function Tensor.__len__> (<class '__main__.TensorBase'>,) (TensorBase([-0.1303, 0.4928, -0.3458, -0.5185, 1.4189, 1.1956, -1.2492,
1.0312, -0.4071, 0.4928, 0.3276, -0.3133, -0.3452, -0.2146,
-0.9111, 0.2789, 0.4154, 1.4559, -1.5123, -1.3805, -0.3555]),) {}Image helpers
make_cross_image
def make_cross_image(
bw:bool=True
):Create a tensor containing a cross image, either bw (True) or color
plt.imshow(make_cross_image(), cmap="Greys");
plt.imshow(make_cross_image(False).permute(1,2,0));
show_image_batch
def show_image_batch(
b, show:function=show_titled_image, items:int=9, cols:int=3, figsize:NoneType=None, **kwargs
):Display batch b in a grid of size items with cols width
show_image_batch(([Image.open(TEST_IMAGE_BW),Image.open(TEST_IMAGE)],['bw','color']), items=2)
Model init
requires_grad
def requires_grad(
m
):Check if the first parameter of m requires grad or not
tst = nn.Linear(4,5)
assert requires_grad(tst)
for p in tst.parameters(): p.requires_grad_(False)
assert not requires_grad(tst)init_default
def init_default(
m, func:function=kaiming_normal_
):Initialize m weights with func and set bias to 0.
tst = nn.Linear(4,5)
tst.weight.data.uniform_(-1,1)
tst.bias.data.uniform_(-1,1)
tst = init_default(tst, func = lambda x: x.data.fill_(1.))
test_eq(tst.weight, torch.ones(5,4))
test_eq(tst.bias, torch.zeros(5))cond_init
def cond_init(
m, func
):Apply init_default to m unless it’s a batchnorm module
tst = nn.Linear(4,5)
tst.weight.data.uniform_(-1,1)
tst.bias.data.uniform_(-1,1)
cond_init(tst, func = lambda x: x.data.fill_(1.))
test_eq(tst.weight, torch.ones(5,4))
test_eq(tst.bias, torch.zeros(5))
tst = nn.BatchNorm2d(5)
init = [tst.weight.clone(), tst.bias.clone()]
cond_init(tst, func = lambda x: x.data.fill_(1.))
test_eq(tst.weight, init[0])
test_eq(tst.bias, init[1])apply_leaf
def apply_leaf(
m, f
):Apply f to children of m.
tst = nn.Sequential(nn.Linear(4,5), nn.Sequential(nn.Linear(4,5), nn.Linear(4,5)))
apply_leaf(tst, partial(init_default, func=lambda x: x.data.fill_(1.)))
for l in [tst[0], *tst[1]]: test_eq(l.weight, torch.ones(5,4))
for l in [tst[0], *tst[1]]: test_eq(l.bias, torch.zeros(5))apply_init
def apply_init(
m, func:function=kaiming_normal_
):Initialize all non-batchnorm layers of m with func.
tst = nn.Sequential(nn.Linear(4,5), nn.Sequential(nn.Linear(4,5), nn.BatchNorm1d(5)))
init = [tst[1][1].weight.clone(), tst[1][1].bias.clone()]
apply_init(tst, func=lambda x: x.data.fill_(1.))
for l in [tst[0], tst[1][0]]: test_eq(l.weight, torch.ones(5,4))
for l in [tst[0], tst[1][0]]: test_eq(l.bias, torch.zeros(5))
test_eq(tst[1][1].weight, init[0])
test_eq(tst[1][1].bias, init[1])autograd jit functions
script_use_ctx
def script_use_ctx(
f
):Decorator: create jit script and pass everything in ctx.saved_variables tof, afterargs`*
script_save_ctx
def script_save_ctx(
static, *argidx
):Decorator: create jit script and save args with indices argidx using ctx.save_for_backward
script_fwd
def script_fwd(
*argidx
):Decorator: create static jit script and save args with indices argidx using ctx.save_for_backward
script_bwd
def script_bwd(
f
):Decorator: create static jit script and pass everything in ctx.saved_variables tof, afterargs`*
grad_module
def grad_module(
cls
):Decorator: convert cls into an autograd function
ismin_torch
def ismin_torch(
min_version
):Check if torch.__version__ >= min_version using packaging.version
notmax_torch
def notmax_torch(
max_version
):Check if torch.__version__ < max_version using packaging.version