| 0 |
ISO_IR 100 |
1.2.840.10008.5.1.4.1.1.7 |
1.2.276.0.7230010.3.1.4.8323329.6904.1517875201.850819 |
19010101 |
000000.00 |
|
CR |
WSD |
|
view: PA |
... |
01 |
ISO_10918_1 |
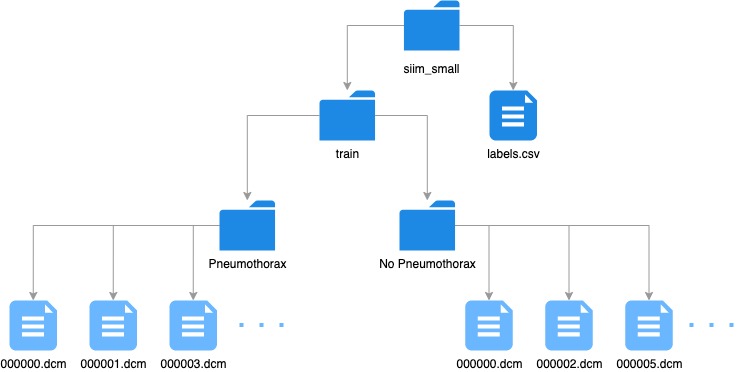
C:\Users\tijme\.fastai\data\siim_small\train\No
Pneumothorax\000000.dcm |
1 |
0.168 |
0 |
254 |
160.398039 |
53.854885 |
0.087029 |
| 1 |
ISO_IR 100 |
1.2.840.10008.5.1.4.1.1.7 |
1.2.276.0.7230010.3.1.4.8323329.11028.1517875229.983789 |
19010101 |
000000.00 |
|
CR |
WSD |
|
view: PA |
... |
01 |
ISO_10918_1 |
C:\Users\tijme\.fastai\data\siim_small\train\No
Pneumothorax\000002.dcm |
1 |
0.143 |
0 |
250 |
114.524713 |
70.752315 |
0.326269 |
| 2 |
ISO_IR 100 |
1.2.840.10008.5.1.4.1.1.7 |
1.2.276.0.7230010.3.1.4.8323329.11444.1517875232.977506 |
19010101 |
000000.00 |
|
CR |
WSD |
|
view: PA |
... |
01 |
ISO_10918_1 |
C:\Users\tijme\.fastai\data\siim_small\train\No
Pneumothorax\000005.dcm |
1 |
0.143 |
0 |
246 |
132.218334 |
73.023531 |
0.266901 |
| 3 |
ISO_IR 100 |
1.2.840.10008.5.1.4.1.1.7 |
1.2.276.0.7230010.3.1.4.8323329.32219.1517875159.70802 |
19010101 |
000000.00 |
|
CR |
WSD |
|
view: PA |
... |
01 |
ISO_10918_1 |
C:\Users\tijme\.fastai\data\siim_small\train\No
Pneumothorax\000006.dcm |
1 |
0.171 |
0 |
255 |
153.405355 |
59.543063 |
0.144505 |
| 4 |
ISO_IR 100 |
1.2.840.10008.5.1.4.1.1.7 |
1.2.276.0.7230010.3.1.4.8323329.32395.1517875160.396775 |
19010101 |
000000.00 |
|
CR |
WSD |
|
view: PA |
... |
01 |
ISO_10918_1 |
C:\Users\tijme\.fastai\data\siim_small\train\No
Pneumothorax\000007.dcm |
1 |
0.171 |
0 |
250 |
166.198407 |
50.008985 |
0.053009 |